Sub-Agents vs Agent Teams
Choosing the right parallelization strategy for your use case
What you'll learn
Two Ways to Parallelize
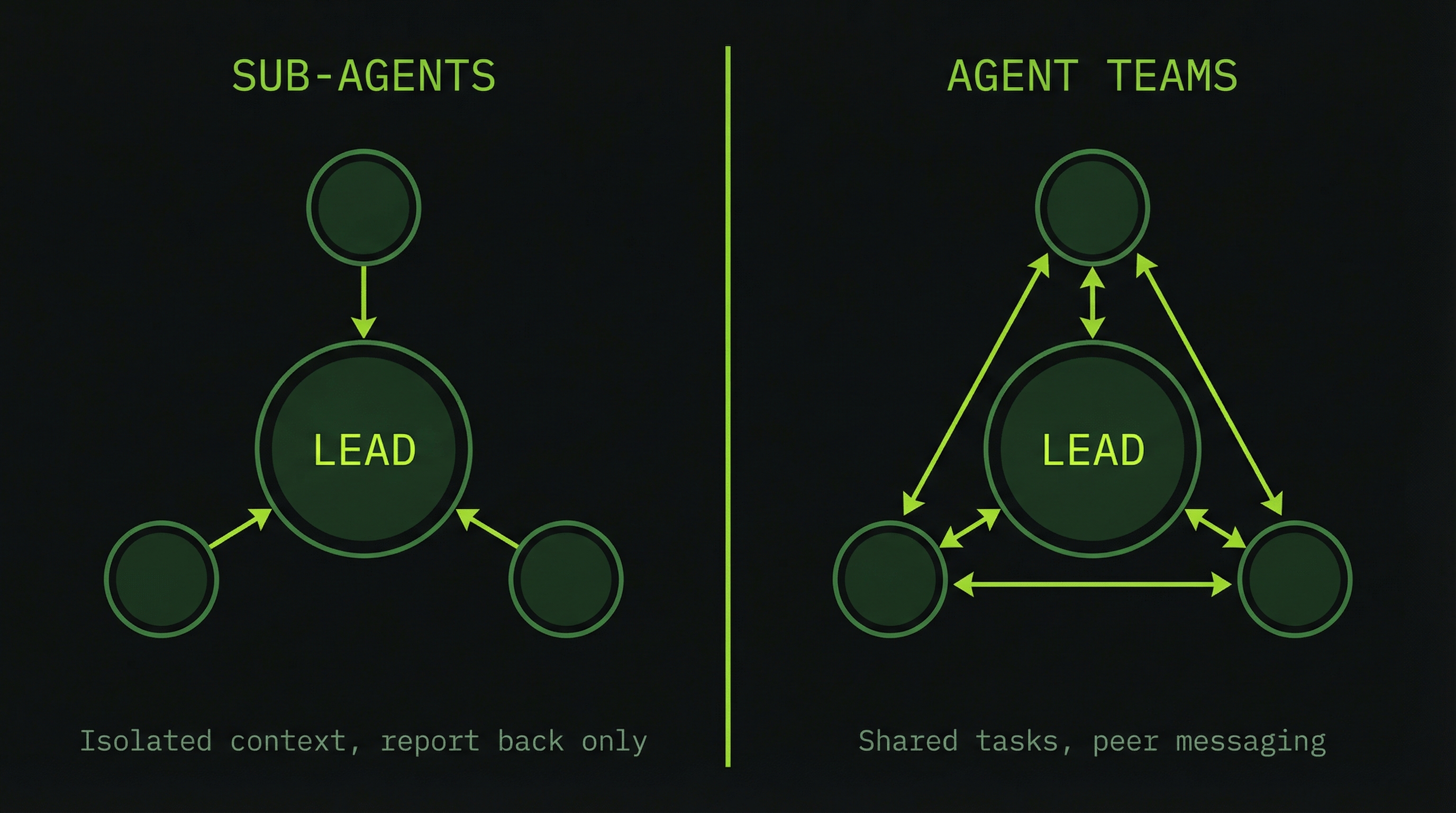
When you have work that benefits from multiple agents running simultaneously, you have two fundamentally different mechanisms to choose from. They look similar from the outside — multiple Claude Code instances running at once — but they differ in how those instances relate to each other. Choosing incorrectly is one of the most common sources of integration failures in multi-agent work.
What Is a Sub-Agent?
A sub-agent is a separate Claude Code instance that the lead spawns to perform an isolated piece of work. It receives a task and a chunk of context from the lead, executes in its own window, and reports only its result back. It has no awareness of other sub-agents running concurrently, no way to message them, and no shared state beyond what the lead explicitly provided at spawn time.
Lead Agent
│
├─ sends: task + context snapshot
↓
Sub-Agent #1 Sub-Agent #2 Sub-Agent #3
(isolated context) (isolated context) (isolated context)
(does work) (does work) (does work)
│ │ │
└──── sends SUMMARY ──┴───── back to ───────┘
LeadThe key word is summary. Sub-agents do not stream their work back in real time — the lead only sees the final result. This makes sub-agents cheap and effective for bounded, independent tasks. It also means the lead has no visibility into what the sub-agent did or discovered along the way, only what it chose to include in its summary.
What Is an Agent Team Teammate?
A teammate is also a separate Claude Code instance, but one that participates in a shared coordination layer. It reads from a shared task list, can send and receive messages from other teammates directly, and the lead maintains ongoing visibility into its work. A teammate is a collaborator; a sub-agent is a contractor you send off and wait to hear from.
Lead Agent
│
└─ creates team
│
Teammate #1 ←──────────────→ Teammate #2
(own context) (own context)
(can message peers) (can message peers)
│ │
└──────── Shared Task List & Mailbox ──────┘
│
Lead (monitors, synthesizes)Comparison at a Glance
| Dimension | Sub-Agent | Agent Team |
|---|---|---|
| Context isolation | Full — own window | Full — own window |
| Peer communication | None (lead only) | Direct messages to any teammate |
| Task coordination | Lead assigns everything | Shared task list, agents self-claim |
| Lead visibility | Results only | Ongoing status and context usage |
| Token cost | Lower (summary return) | Higher (full instances + coordination) |
| Best for | Research, analysis, reporting | Implementation, complex coordination |
| Use when | Work is fully independent | Agents need to discuss and adjust |
The Decision Tree
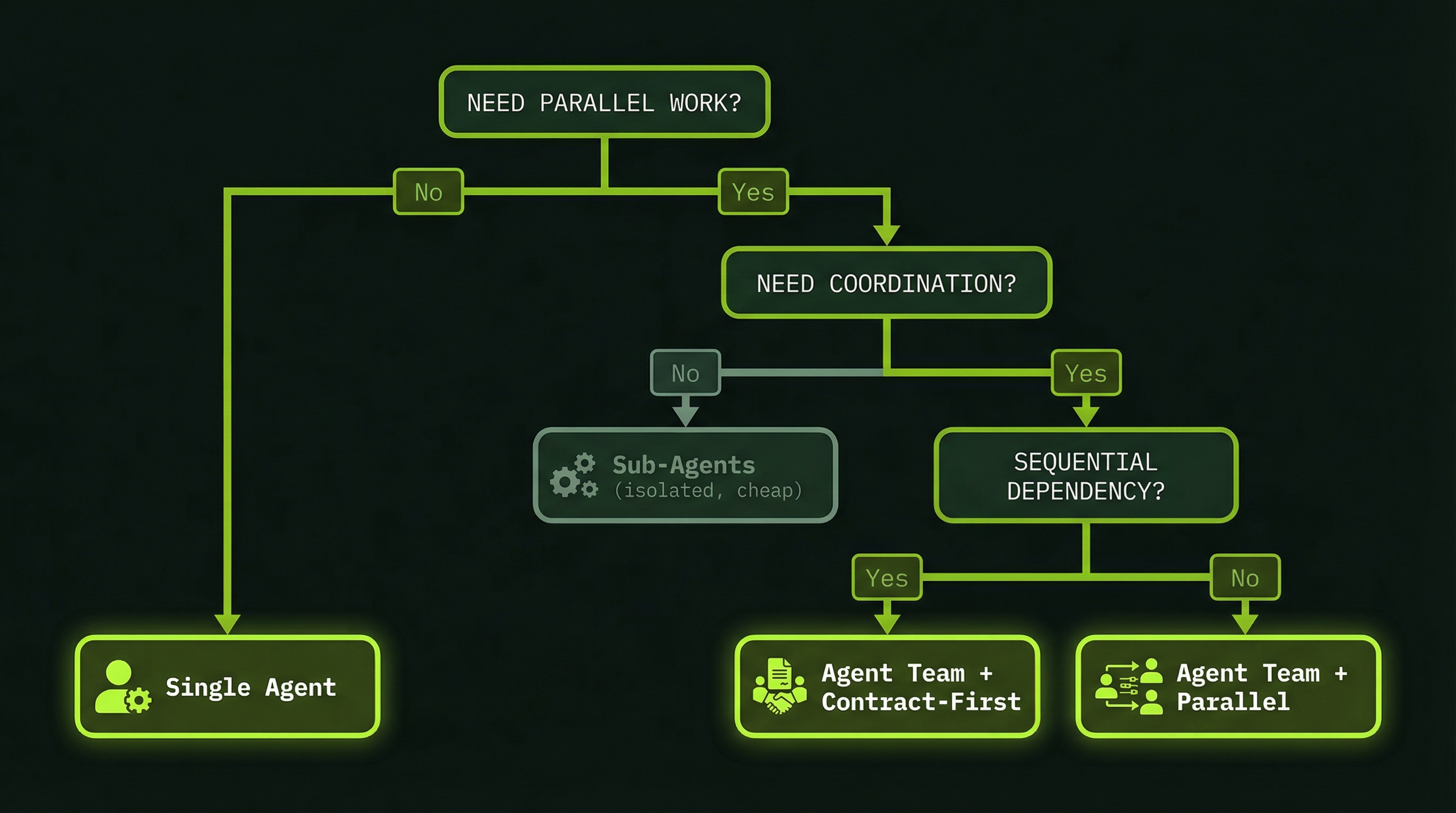
In practice, the routing decision comes down to a single core question: do the workers need to communicate with each other? If they do not — if each piece of work can be completed with only the information the lead provided at spawn time — use sub-agents. If they do, use a team.
Task requires multiple workers
↓
Do workers need to communicate with each other?
│
├─ NO → Use Sub-Agents
│ Example: "Analyze 5 folders and report back"
│ Each sub-agent gets one folder, works independently,
│ returns its analysis. Lead synthesizes 5 reports.
│
└─ YES → Use Agent Team
Example: "Build payment feature (DB + API + Frontend)"
Backend may change API contract mid-build.
Frontend needs to know immediately.
Database needs to communicate schema to both.
│
Further decision:
├─ Agents can work fully in parallel?
│ └─ Simple Agent Team
│ Example: 3 code reviewers, independent files
│
└─ Agents have strict ordering/dependencies?
└─ Agent Team + Contract-First (see Module 8)
Example: DB schema → Backend → Frontend chainA second filter: if you are highly cost-sensitive and the work does not strictly require peer communication, lean toward sub-agents even if coordination would be theoretically useful. The lead can act as a coordination layer at lower cost than running full peer-to-peer messaging infrastructure.
Real-World Routing Examples
Use Sub-Agents: Code Review
Three reviewers looking at different concerns in the same codebase are almost always appropriate for sub-agents. A security reviewer does not need to know what the performance reviewer found before it can do its job. The work is genuinely independent:
Sub-Agent 1: Review all authentication and authorization code
Sub-Agent 2: Profile hot paths and identify N+1 query patterns
Sub-Agent 3: Check test coverage gaps and assertion quality
Lead: Receives three summaries, merges into a single review report
Token cost estimate:
Lead context: ~20,000 tokens
3 × sub-agent work: ~8,000 tokens each
Total: ~44,000 tokensThe reviews happen in parallel, the lead aggregates results, and no sub-agent needed to know what the others were doing.
Use Agent Teams: Full-Stack Feature
Building a payment feature that spans database, API, and frontend layers requires real-time coordination. The database agent's schema decisions directly constrain what the backend can build. The backend's API contract directly constrains what the frontend builds. These dependencies are not resolvable at spawn time — they emerge during development:
Teammate 1: Database — designs schema, runs migrations, sends schema contract
Teammate 2: Backend — implements API against DB contract, sends API contract
Teammate 3: Frontend — builds billing UI against API contract
Lead: Orchestrates contract handoffs, monitors progress
Token cost estimate:
Lead context: ~50,000 tokens
3 × teammate work: ~30,000 tokens each
Total: ~140,000 tokens
Why the extra cost is worth it:
- 3–5 minutes wall time vs. 15–20 minutes sequential
- Zero integration failures from API mismatches
- Teammates self-adjust when contracts changeThe Failure Mode Sub-Agents Cannot Handle
This is important enough to dwell on. There is a specific failure mode that sub-agents are architecturally incapable of preventing, and it is surprisingly common in full-stack work.
Sub-Agent 1 (building API): decides to use /api/payments/process
Sub-Agent 2 (building frontend): assumes the endpoint is /api/pay/checkout
Both agents pass their own unit tests. Both complete successfully. The lead receives two summaries that look fine in isolation.
Integration fails. There is no visibility into the conflict until something breaks in production.
With an agent team, this divergence never happens. When BackendAgent finalizes its endpoint, it sends a direct message to FrontendAgent: "I'm using /api/payments/process — update your fetch calls." FrontendAgent adjusts immediately. The integration works because the agents talked to each other.
This is the fundamental reason to choose teams over sub-agents for implementation work: sub-agents optimize for isolation; teams optimize for coherence.
The Hybrid Approach: Research Then Implement
In practice, many large tasks benefit from a two-phase approach that uses sub-agents for the exploratory work and an agent team for implementation. This gives you the cost efficiency of sub-agents where work is independent and the coordination power of teams where it is not.
PHASE 1: Research (sub-agents, cheap and parallel)
Sub-Agent 1: Analyze current codebase architecture
Sub-Agent 2: Investigate dependency versions and compatibility
Sub-Agent 3: Check for existing patterns to reuse
Lead receives 3 research reports
Lead creates a detailed implementation plan with contracts
PHASE 2: Implementation (agent team, coordinated)
Teammate 1: Database layer — works from research findings
Teammate 2: Backend layer — coordinates with Database
Teammate 3: Frontend layer — coordinates with Backend
All share a task list seeded from the Phase 1 planPhase 1 typically costs 20,000–40,000 tokens and takes 5–8 minutes. Phase 2 costs more but starts from a much better-informed position — the lead's plan is grounded in actual codebase analysis rather than assumptions. Total sessions that use this pattern almost always have fewer mid-implementation surprises, which offsets the upfront research cost.
Token Cost Comparison: A Concrete Scenario
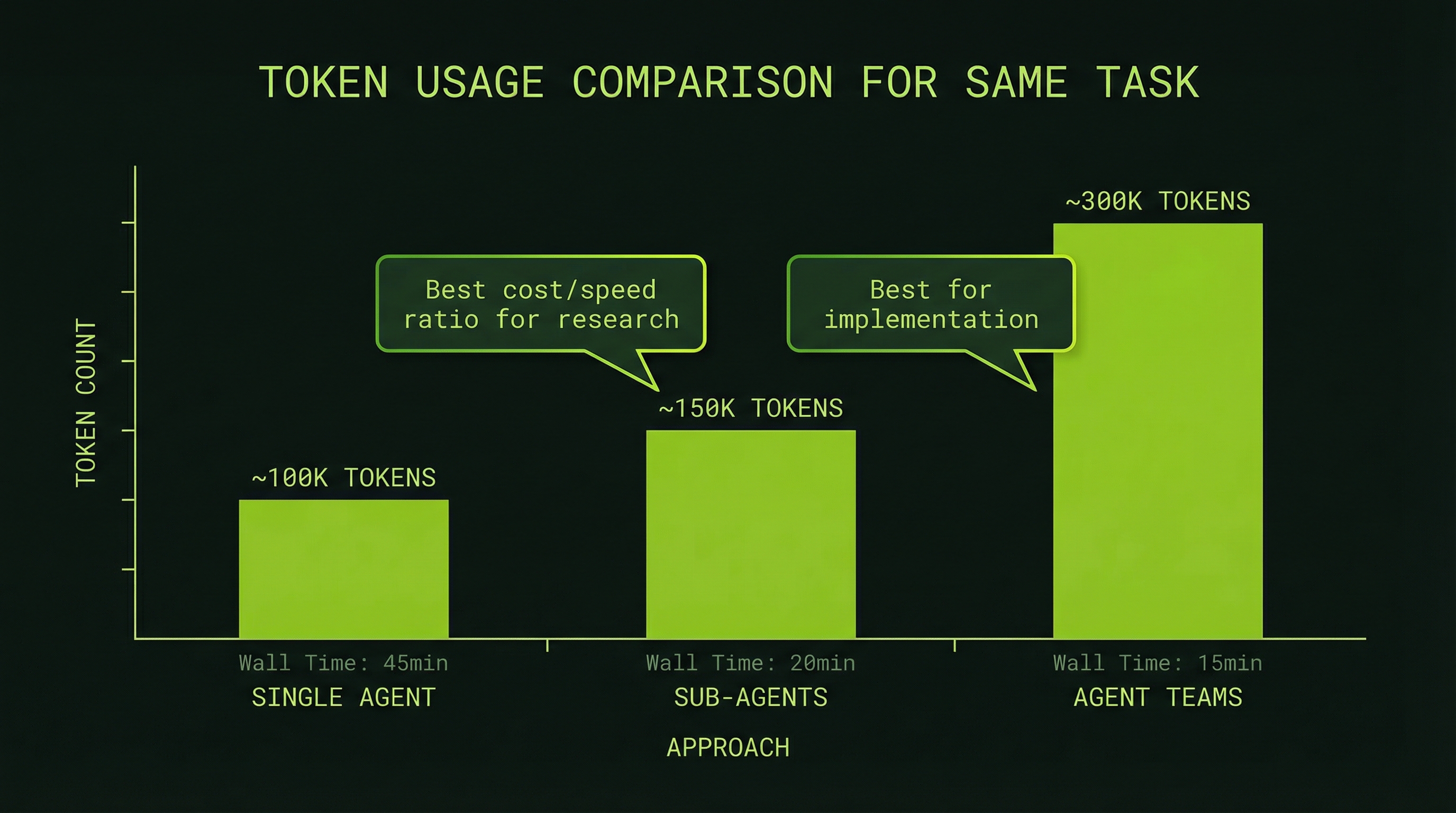
To make the tradeoffs tangible, here are approximate token costs for adding an "export to PDF" feature across three approaches (these are illustrative estimates — actual costs vary by codebase and task complexity):
Approach 1: Single Sequential Session
Read codebase: 10,000 tokens
Plan feature: 5,000 tokens
Implement backend: 20,000 tokens
Implement frontend: 15,000 tokens
Write tests: 8,000 tokens
─────────────────────────────────
Total: 58,000 tokens (~15–20 min wall time)Approach 2: Sub-Agents for Research, Lead for Implementation
Lead planning: 5,000 tokens
Sub-Agent 1 (backend research): 8,000 tokens
Sub-Agent 2 (frontend research): 8,000 tokens
Lead implementation: 30,000 tokens
─────────────────────────────────
Total: 51,000 tokens (~8–10 min wall time)
Benefit: cleaner research phase, faster executionApproach 3: Full Agent Team
Lead planning: 5,000 tokens
Teammate 1 (backend): 25,000 tokens
Teammate 2 (frontend): 20,000 tokens
Teammate 3 (tests): 12,000 tokens
Lead synthesis: 5,000 tokens
─────────────────────────────────
Total: 67,000 tokens (~3–5 min wall time)
Benefit: fastest, fully coordinated, zero integration driftThe pattern is clear: agent teams cost more per session but complete faster and with better integration quality. For features where speed and correctness matter — anything shipping to production — the extra 15,000 tokens is almost always worth it. For pure research or analysis tasks, sub-agents save meaningful cost with no quality loss.
Team Size and Diminishing Returns
Token costs scale linearly with agent count: three agents cost roughly three times as much as one, five agents cost five times as much. But the coordination benefit does not scale at the same rate. Beyond five or six agents, the overhead of inter-agent communication, task contention, and lead management begins to eat into the parallelism gains.
- 3 agents: Strong parallelism, manageable coordination overhead. The default starting point.
- 5 agents: Good for complex features with distinct layers. Monitor the lead's context carefully.
- 8+ agents: Diminishing returns set in. Consider whether the task is actually parallelizable at that granularity, or whether you would be better served by sequential phases.
Start with 3 agents. Add a 4th or 5th only when you have clearly distinct work streams that genuinely cannot share an agent without context overload.
Routing Decision Algorithm
When you are unsure which approach to use, run through this mental algorithm:
Is this research-only (analysis, reporting, investigation)?
→ Sub-Agents
Is this simple and sequential (one thing at a time)?
→ Sub-Agent or single session
Does the work require parallel collaboration across layers?
→ Agent Team
Am I extremely cost-sensitive and coordination is optional?
→ Sub-Agents with lead synthesis
Is speed the priority and correctness is critical?
→ Agent Team
Uncertain? Default to Agent Teams for complex implementation work.