Cost Optimization & Best Practices
Managing token spend, choosing models per agent, and production patterns
What you'll learn
Understanding the Cost of Agent Teams
Agent teams are powerful, but they are not free. Every agent you spawn consumes tokens for initialization, context loading, tool calls, and inter-agent communication. Before you can optimize costs, you need to understand where they come from.
The cost of a single implementation agent for a moderately complex task breaks down roughly as follows (these are approximations — actual usage varies by task complexity):
Spawn initialization: ~500 tokens
Project context loading: ~2,000 tokens
8 tasks × tool calls each: ~18,400 tokens (avg 300 overhead + 2,000 work)
Inter-agent messaging: ~500 tokens
─────────────────────────────────────────
Total per agent: ~21,400 tokens
3-agent full-stack team:
21,400 × 3 = ~64,200 tokens ≈ $1.28 at current ratesThat $1.28 is not a problem if the team saves you 40 minutes of work. It is a problem if the team produces output that requires substantial rework, effectively doubling your spend. Cost optimization is therefore inseparable from quality: the single biggest lever for reducing token cost is writing better plans upfront, which reduces rework.
Strategy 1: Right-Sizing the Team
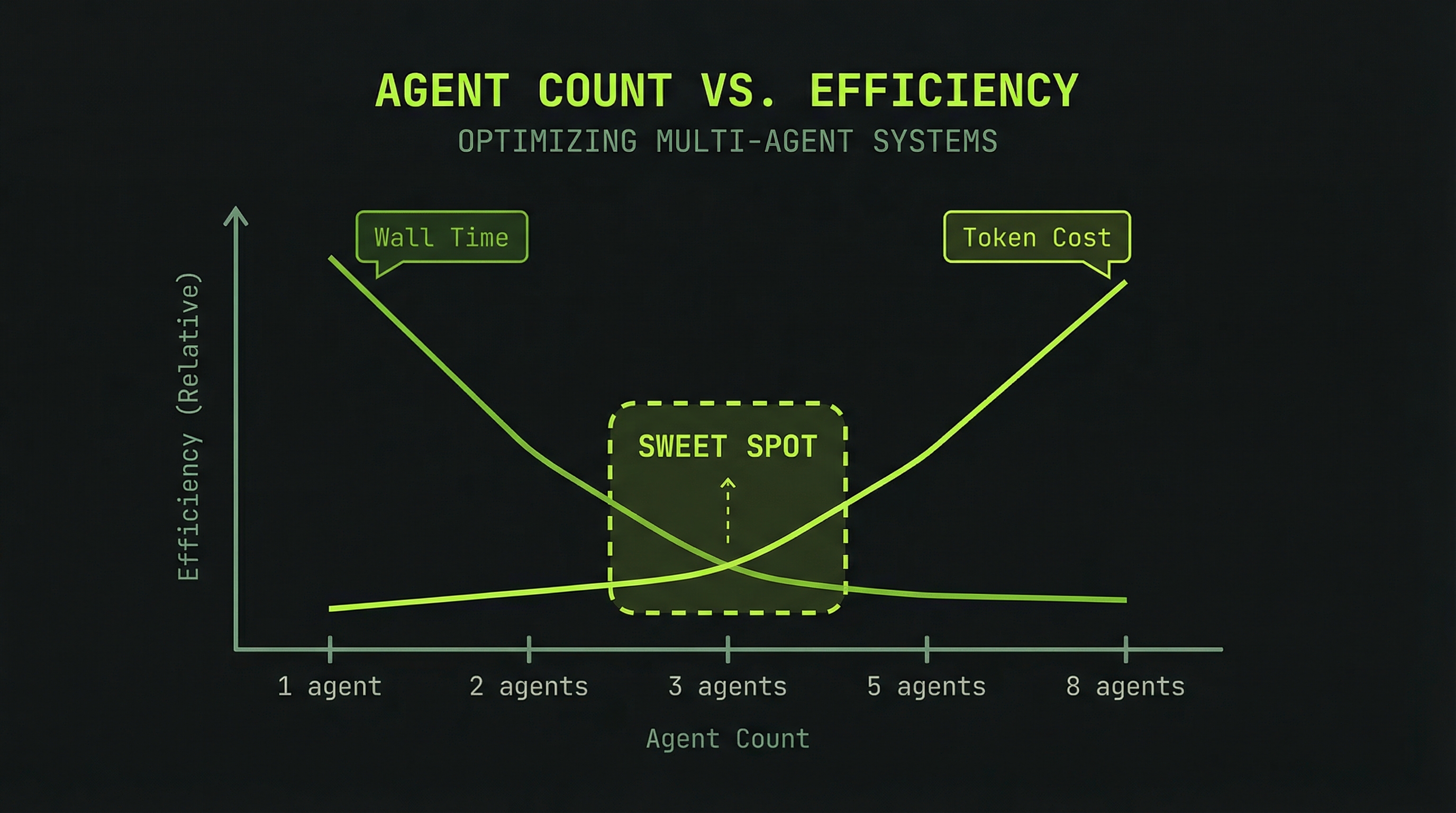
More agents is not always better. There is a sweet spot where parallelism benefit exceeds coordination overhead, and it's smaller than most people expect.
1 agent: 35,000 tokens | 15 min | Low efficiency
(no parallelism benefit, full overhead)
2 agents: 55,000 tokens | 8 min | Medium
(modest parallelism, coordination cost)
3 agents: 65,000 tokens | 5 min | High ✓ optimal
(good parallelism, manageable overhead)
5 agents: 105,000 tokens | 4 min | Medium
(diminishing time return, overhead climbs)
8 agents: 170,000 tokens | 4 min | Low
(coordination overhead exceeds benefit)The 3-agent team is the most efficient in most real-world cases. You save roughly 10 minutes over serial execution, and you spend about 65,000 tokens instead of 35,000—a 85% cost increase for a 67% time reduction. That's a good trade when your time is worth more than $0.30 per 10 minutes saved.
The 8-agent team saves virtually no additional time over 5 agents while costing 62% more. You've paid for coordination overhead without buying meaningful speed. Start at 3, go to 5 as a maximum for most tasks.
Strategy 2: Task Granularity
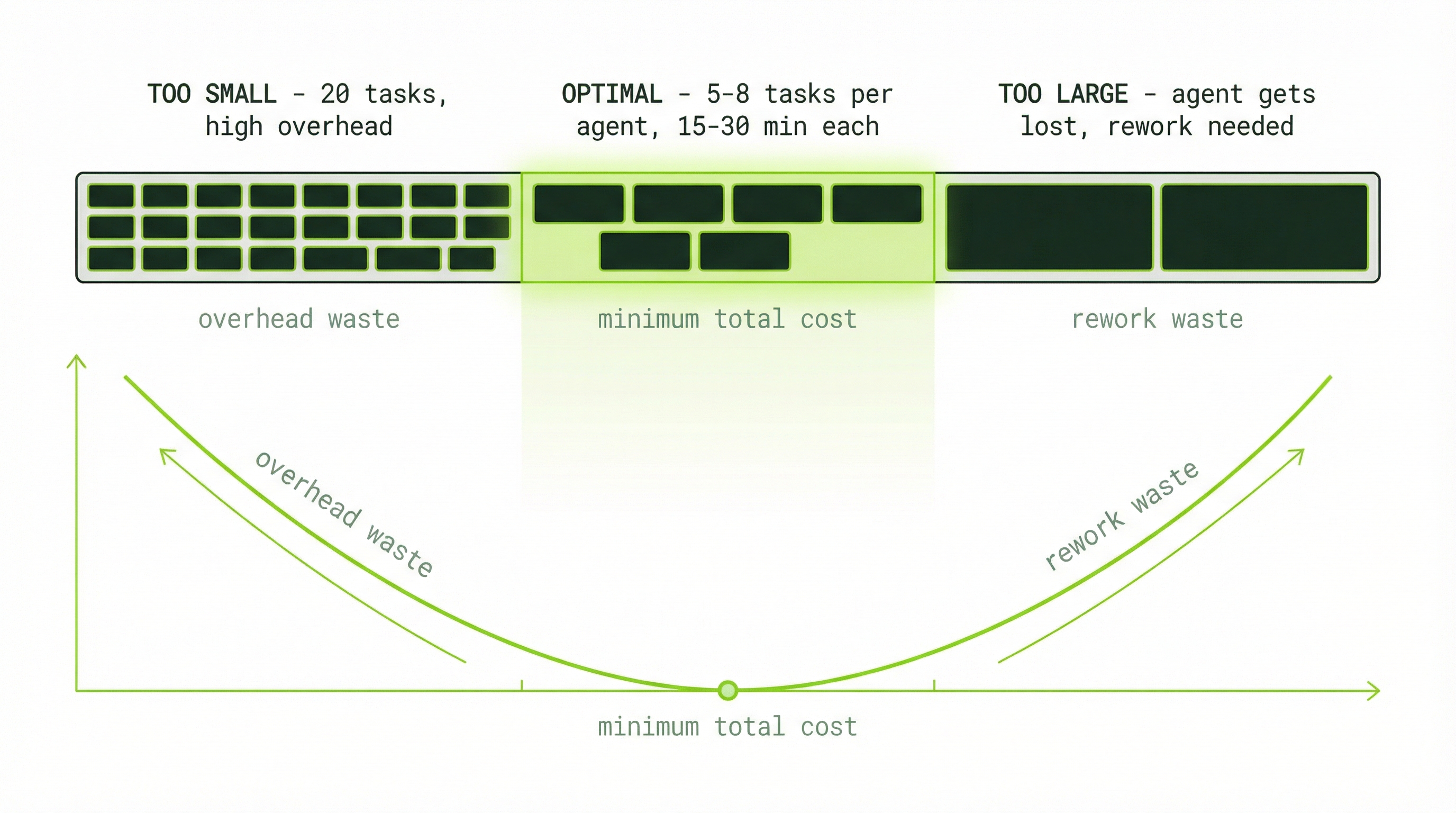
Task size affects cost in two directions. Tasks that are too small create disproportionate overhead from repeated initialization and context-switching. Tasks that are too large create a different problem: agents get stuck, make wrong assumptions, and require reassignment—which costs rework tokens on top of the original work.
# Too fine-grained (20 tasks of 30 min each would be better as 8):
20 tasks × 300 tokens overhead = 6,000 tokens in overhead alone
Agents spend significant context just tracking what they've done
# Too coarse-grained (2 tasks covering too much ground):
Agent works for 20 minutes then hits an ambiguity
Misinterprets the requirement
Lead reassigns with corrections
Rework costs 5,000+ additional tokensThe optimal task size for most agent work is 5–8 tasks per agent, each representing 15–30 minutes of focused execution. Tasks in this range are specific enough to execute without ambiguity, but substantial enough that the overhead is a small fraction of the total work.
Strategy 3: Planning Before Spawning
This is the highest-leverage cost optimization available, and it costs almost nothing to implement. Eighty percent of agent team failures—and the rework costs that follow—trace back to insufficient upfront planning.
# Without planning: agents guess and fill gaps themselves
"Build the payment feature, figure it out as you go"
Result:
- Agents make different assumptions about the schema
- Frontend uses field names that don't match the API
- Integration requires significant rework
- Total tokens: ~80,000 (65,000 work + 15,000 rework)
# With planning: agents execute against defined contracts
"Here's the schema, here's the API contract,
here are the UI mockups. Build against these."
Result:
- Integration works on first attempt
- No rework phase
- Total tokens: ~65,000The planning phase itself costs approximately 3,000–5,000 tokens if done in a separate session before spawning the team. That investment reliably saves 10,000–20,000 tokens in rework. The ROI on good planning is consistently 3:1 or better.
Strategy 4: Model Selection by Role
Not all agents need the same model. The orchestrator and lead agent make the most complex decisions—architectural choices, dependency resolution, synthesis—and warrant the most capable model. Implementation agents execute well-defined tasks that don't require the same reasoning depth.
Opus 4.6 → Lead/orchestrator, complex architecture decisions
$5 / MTok input, $25 / MTok output
Use when: reasoning, synthesis, ambiguous problems
Sonnet 4.6 → Implementation agents, standard code writing
$3 / MTok input, $15 / MTok output
Use when: well-defined tasks with clear acceptance criteria
Haiku 4.5 → Simple analysis, formatting, documentation
$1 / MTok input, $5 / MTok output
Use when: straightforward transformation tasksMTok = million tokens. Pricing changes frequently. Check the Claude pricing page for current rates before budgeting.
A concrete example for a three-agent team (input tokens only, for simplicity):
Lead (Opus): 10K tokens × $5/MTok = $0.050
Backend (Sonnet): 20K tokens × $3/MTok = $0.060
Frontend (Sonnet): 20K tokens × $3/MTok = $0.060
────────────────────────────────────────────────────────
Total input cost: $0.170
vs. all-Opus team:
50K tokens × $5/MTok = $0.250 (47% more expensive)The savings compound across many team runs. Mixed-model routing consistently saves 30–50% compared to running all agents on the most capable model.
Strategy 5: Context Refresh for Long Runs
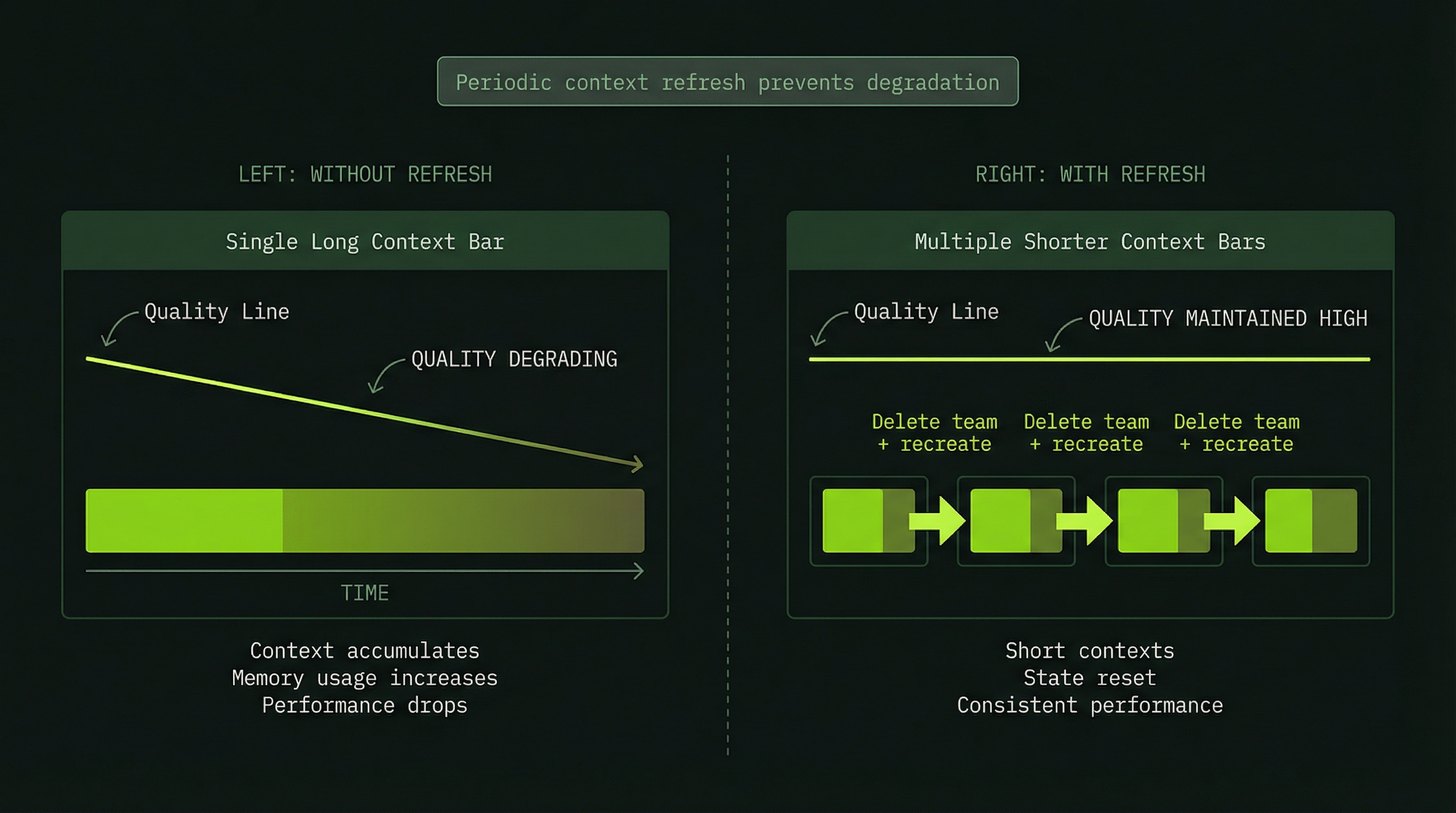
When agents hit 85%+ context, performance degrades and compaction begins silently discarding early context. Rather than letting this happen, a planned context refresh—spinning down the team and starting fresh with a summary—is almost always worth the cost.
# The handoff prompt:
"Excellent progress. Let me summarize where we are
so we can start a fresh team with clean context.
Completed: [list of finished work]
In-progress: [what was being worked on]
Remaining: [what's left to do]
Key contracts: [interfaces defined so far]"
# Fresh team startup cost:
Context handoff summary: ~2,000 tokens
New team initialization: ~1,500 tokens
─────────────────────────────────────────
Refresh cost: ~3,500 tokens
vs. compaction penalty:
Degraded performance: +8,000–15,000 tokens wasted
Silent context loss: requires re-explanation
─────────────────────────────────────────
Compaction cost: ~8,000–15,000 tokensThe refresh approach costs 3,500 tokens but prevents 8,000–15,000 tokens of degraded performance. Take the refresh.
Best Practice 1: The Planning-First Workflow
The most important operational practice is planning before spawning. This means investing in a planning phase—either via a single-agent research session or direct conversation—before any team is created.
The planning phase should produce: a named team with specific roles, a detailed task breakdown with acceptance criteria, a dependency graph showing which tasks must complete before others can start, and interface contracts between modules. With these artifacts in hand, the team execution phase becomes a matter of execution rather than discovery.
Best Practice 2: Specific, Testable Tasks
The quality of your task descriptions directly determines whether agents execute correctly or spiral into guesswork. Every task should answer four questions: What exactly needs to be built? What does success look like? What inputs are available? What output or artifact should be produced?
# Vague task (avoid):
"Fix the authentication bugs"
# Specific, testable task (use this):
"Fix the JWT token expiry check in src/auth/middleware.ts.
The current check uses > instead of >=, causing valid tokens
to be rejected exactly at expiry.
Acceptance criteria:
- A token expiring at T should be accepted at time T
- A token expiring at T should be rejected at time T+1
- All existing auth tests pass
- Add a test for the exact-expiry edge case"Best Practice 3: Communication Discipline
Agent teams that don't communicate contracts explicitly will produce integration failures. The solution is to build communication checkpoints into the task structure itself—not as an afterthought, but as a required deliverable for each phase.
- Each phase must end with a contract message to the next downstream agent.
- Define what the message must contain in the original task description.
- Verify communication happened by checking the message log before proceeding.
Best Practice 4: Context Budget Management
Treat agent context like memory in a constrained system. Proactively manage it rather than waiting for automatic compaction to degrade your results. The rule: no agent should reach 90% context without explicit action from you or the lead.
Practical techniques for staying within budget: break long tasks into smaller checkpointed steps, commit code frequently (reduces the amount of code-state held in context), instruct agents to send regular summaries rather than keeping everything in working memory, and start fresh team sessions for phase 2 of multi-phase projects.
Best Practice 5: Always Validate Output
A status of "all tasks marked complete" is not the same as "the feature works." Agents can mark tasks complete when they believe the work is done, but integration failures, subtle bugs, and contract mismatches are common enough that you should always run explicit validation before considering a team session finished.
Validation checklist:
✓ End-to-end test: Does the full feature work from user perspective?
✓ Integration: Do all layers communicate correctly?
✓ Contract compliance: Did agents follow the agreed interfaces?
✓ Tests pass: Does the test suite pass cleanly?
✓ No regressions: Did existing functionality stay intact?Best Practice 6: Iterative Improvement
Your first team run for a new problem type will not be perfect. Expect 70% success—some tasks will need rework, some contracts will be imprecise. This is normal. The key is to analyze what went wrong and fix the root cause before the next run, not just fix the output.
Keep notes on what caused failures: was it a vague task description, a missing contract, an incorrect dependency order, or an assumption that should have been an explicit clarification? After three iterations on the same pattern, you should be at 95%+ success and ready to package it as a reusable skill.
Best Practice 7: Cost Awareness Before Every Spawn
Build the habit of estimating cost before spawning any team. This keeps you honest about whether a team is the right tool for the job and gives you a budget to stay within.
Pre-spawn checklist:
─────────────────────────────────────────────
1. Could a single agent do this?
→ If yes: use single agent, save 50%+ on cost
2. Could subagents (no communication) do this?
→ If yes: use subagents, save 30%+ on coordination
3. Do agents actually need to communicate contracts?
→ If yes: use a team
4. Cost estimate:
Lead: 5,000–10,000 tokens
Per agent: 10,000–50,000 tokens
Total range: 35,000–200,000 tokens
5. Is the ROI positive?
Saves >20% of your time? → Yes
Prevents likely rework? → Yes
Exploring new territory? → Maybe (higher uncertainty)Common Pitfalls Reference
| Pitfall | Root Cause | Fix |
|---|---|---|
| Agents edit same files | Overlapping task scopes | Assign non-overlapping file ownership per agent |
| Integration fails | No contracts defined | Define interface contracts before spawning |
| Token budget exceeded | Vague tasks causing rework | Write specific acceptance criteria for every task |
| Agent stuck for 5+ min | Ambiguous task or missing dependency | Reassign with clarified requirements |
| Context overflow | Long execution without checkpoints | Commit early and often; start fresh team for phase 2 |
| High cost, low output | Team too large for task | Use 3 agents, not 6+ |
| Silent integration failures | Agents assumed without messaging | Require explicit contract messages at phase boundaries |
| Expensive rework loops | Assumptions not verified upfront | Ask clarifying questions before plan is finalized |
Before spawning a team, fill in this quick estimate to keep spending conscious:
Project: [name]
Team size: 3 agents
Est. duration: 10 min
─────────────────────────────
Lead planning: 3,000
Database agent: 15,000
Backend agent: 18,000
Frontend agent: 16,000
Validation: 2,000
─────────────────────────────
TOTAL ESTIMATE: 54,000 (~$1.08)
Budget approved: YES → proceed
Budget declined: NO → use subagents or break into phases