Advanced Use Cases
Code reviews, competing hypotheses, cross-platform parity, and writing workflows
What you'll learn
Translating Patterns into Practice
The previous modules taught you the mechanics of agent teams: how to spawn them, manage their lifecycle, share contracts, and observe their behavior. This module is about applying those mechanics to problems worth solving. Each use case below represents a pattern you can use immediately on real work—and each one illustrates something that agent teams do fundamentally better than a single agent.
The common thread across all of them is cognitive isolation: giving each agent an independent context prevents the cross-contamination of ideas that makes a single agent less reliable at complex, multi-dimensional analysis.
Use Case 1: Code Review with Competing Perspectives
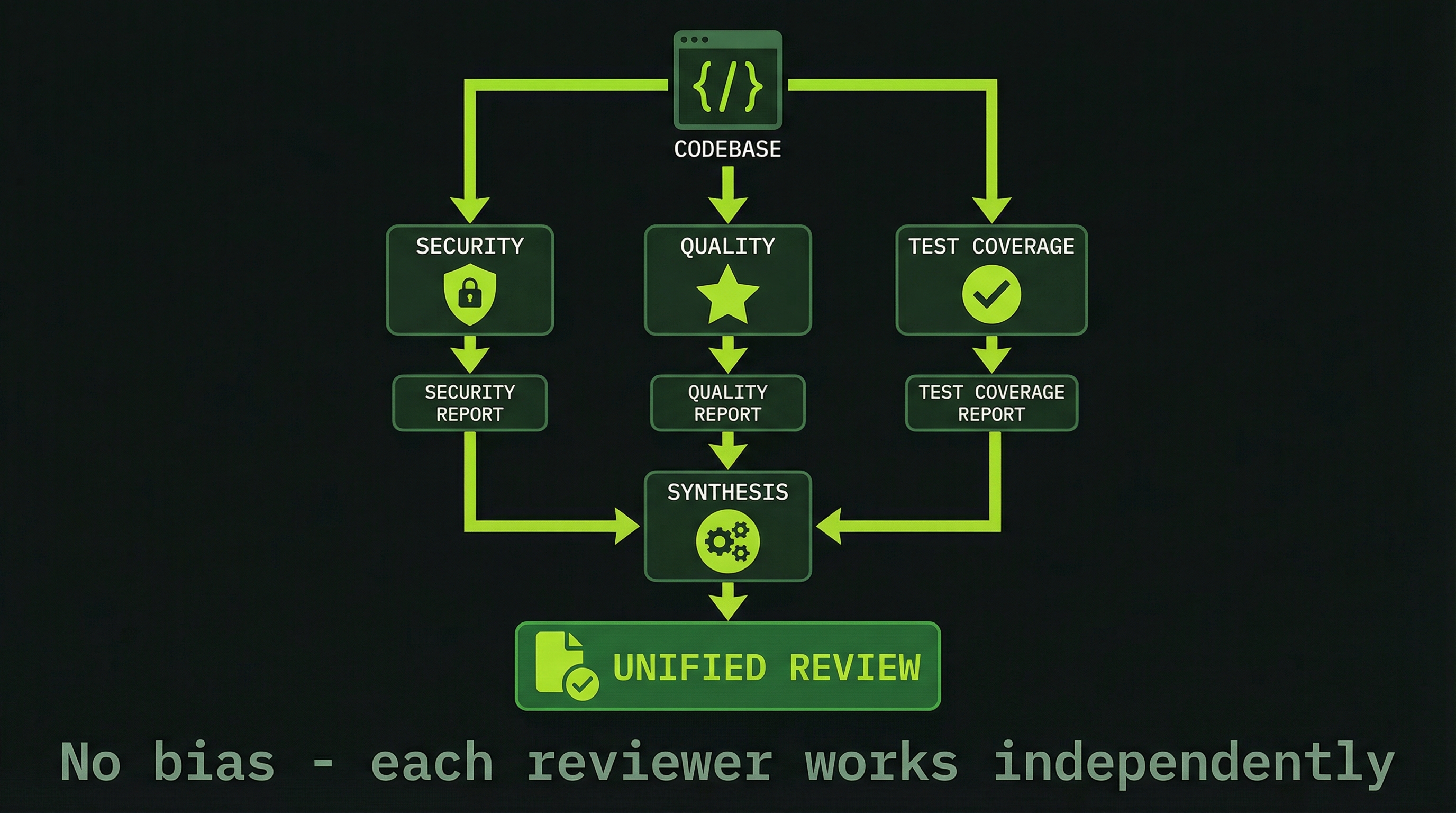
Code review is the canonical multi-agent use case because the problem structure maps perfectly to what teams do well. A single agent reviewing code will notice security issues early in its analysis and then—because those findings now dominate its context—subtly underweight performance and test coverage. It's not failure; it's how attention works.
With a team, you assign each dimension to a dedicated reviewer who builds their analysis from scratch, in isolation, without knowing what the others found:
TEAM COMPOSITION:
SecurityReviewer → SQL injection, XSS, auth bypasses, crypto usage
PerformanceReviewer → Query complexity, N+1 patterns, caching opportunities
TestReviewer → Coverage gaps, missing edge cases, test quality
ArchitectureReviewer → Design patterns, coupling, extensibility
EXECUTION PATTERN:
1. Each reviewer reads the same diffs independently
2. Each forms their own findings without seeing others' work
3. Each sends their report to the lead
4. Lead synthesizes into a single prioritized reviewThe synthesis step is important. You're not just concatenating four reports—you're asking the lead to identify conflicts (security fix that creates a performance regression), prioritize across dimensions, and present a coherent action plan.
Create a code review team with three reviewers:
1. Security Reviewer:
Focus: SQL injection, XSS, authentication flaws, crypto vulnerabilities
2. Performance Reviewer:
Focus: DB query patterns, algorithm complexity, caching opportunities
3. Test Reviewer:
Focus: Coverage gaps, test quality, missing edge cases
Each reviewer analyzes the same diffs independently.
Then each sends findings to lead.
Lead produces one consolidated, prioritized review.
Diffs: [paste or attach your git diff here]The power isn't just parallelism—it's isolation. Each reviewer builds their mental model of the code independently, which means a subtle authentication flaw won't be overshadowed by a more visible performance issue. Independent context is what makes this qualitatively better than a single-agent review with multiple personas.
Use Case 2: Full-Stack Feature Development
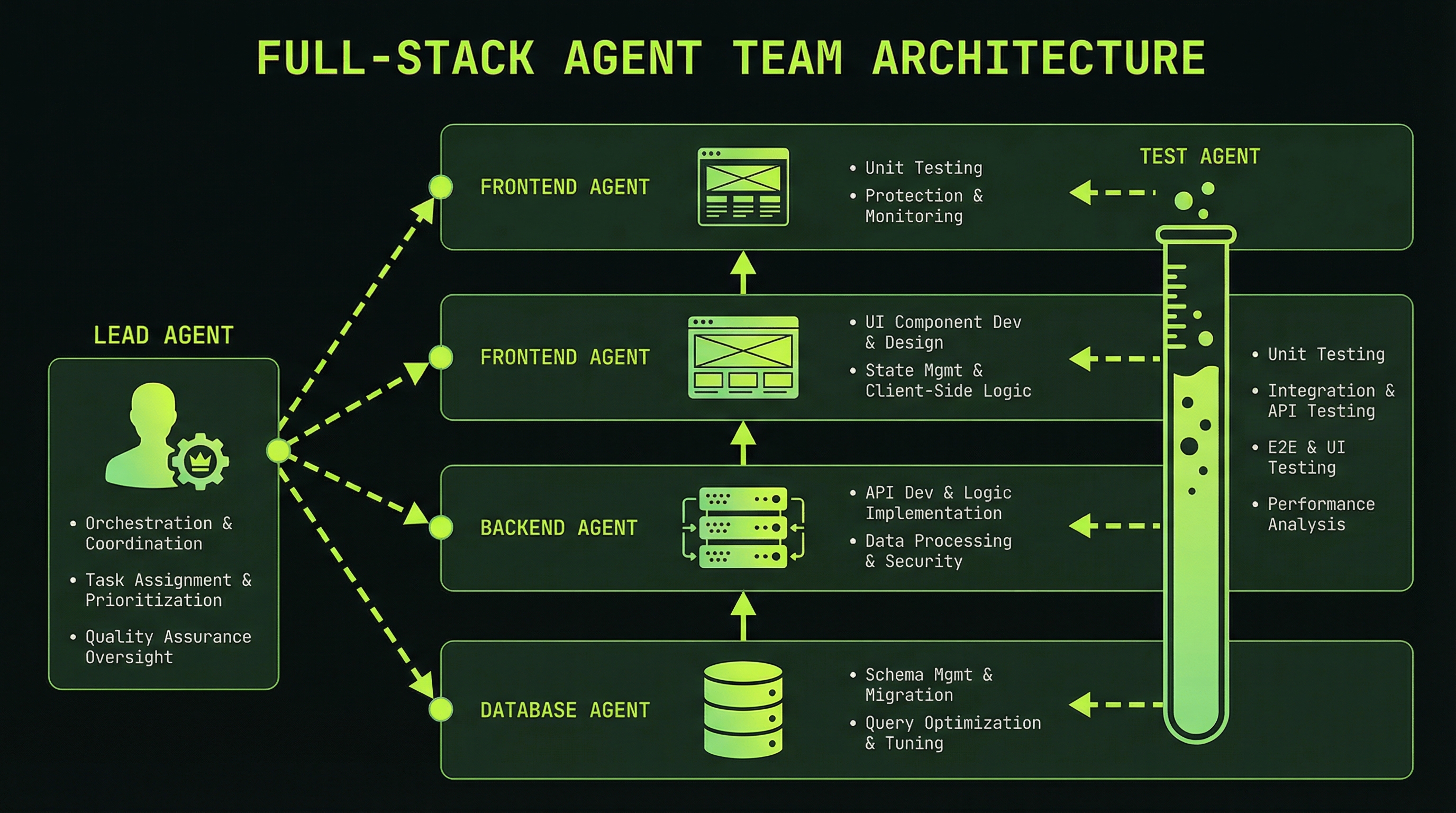
Building a feature from database schema to UI is a classic contract-chain problem. Each layer depends on the layer below it, but within that dependency structure there are significant opportunities for parallelism. The key insight is that the frontend doesn't need to wait for the backend to be fully implemented—it just needs the API contract.
DEPENDENCY CHAIN:
Database → Backend → Frontend → Tests
PARALLEL OPPORTUNITY:
While Backend builds against the DB schema,
Frontend can build component skeletons and mock data
using only the API contract — not the live implementation.Here is a full prompt template for a four-agent feature team:
Create a feature team to build [feature description].
Database Agent:
- Design the user_accounts table with token_balance INT
- Add appropriate indexes for lookup performance
- Write the migration script
- When done: send schema contract to Backend
Backend Agent:
- Wait for schema contract from Database
- Implement POST /api/payment/process
- Implement GET /api/balance
- Write business logic for token deduction with atomicity
- When done: send API contract to Frontend
Frontend Agent:
- On receipt of API contract: build billing page UI
- Implement purchase flow with loading and error states
- Connect to live API endpoints
- When done: notify TestAgent
Test Agent:
- Write end-to-end tests for the full payment flow
- Validate integration between all three layers
- Report any test failures with reproduction stepsNotice that TestAgent starts only after all three layers are done, but the other three can start in near-parallel once the schema is defined. In practice, a four-agent feature team that might take 45 minutes sequentially often completes in 12–15 minutes.
Use Case 3: Competing Hypotheses for Debugging
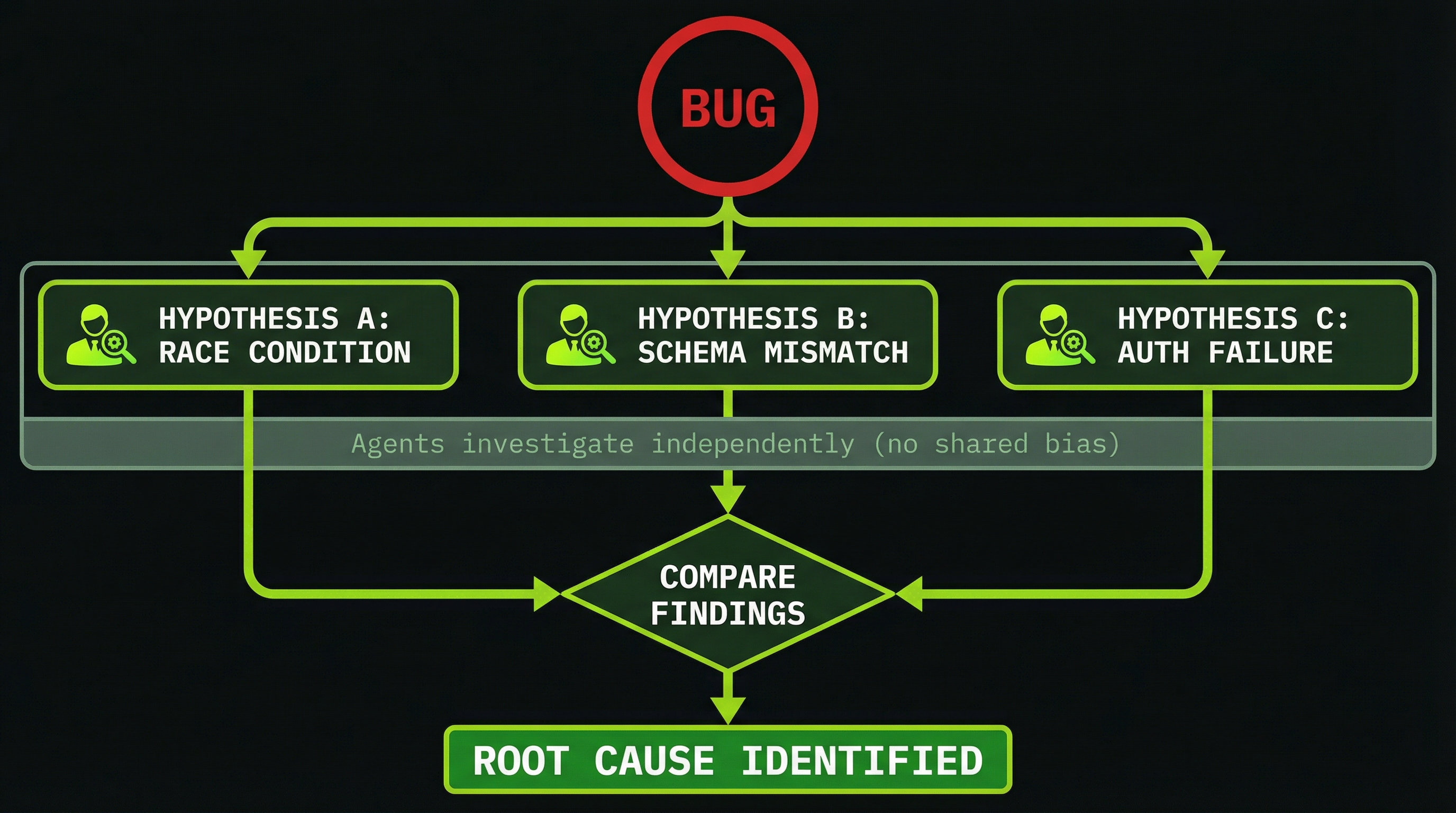
Debugging intermittent failures is one of the most frustrating problems in software. A single agent investigating a race condition will form a hypothesis within its first few minutes and then—because it's built context around that hypothesis—will interpret subsequent evidence through that lens. This is exactly how engineers miss the real root cause for hours.
The competing hypotheses pattern assigns one agent per theory. Each investigates their theory independently, runs experiments, and reports their evidence. The lead then evaluates all theories against the evidence and determines which is most consistent with the observed behavior.
BUG: Users report missing tokens after payment (~10% of the time,
only under high load, balance decreases then reverts)
COMPETING THEORIES:
1. Database query returning stale data (read-after-write issue)
2. Frontend displaying a cached balance (stale client state)
3. Race condition in async token deduction
4. Error handler consuming the exception silently
Create 4 investigators. Each gets one theory.
Each investigator: independently examine the codebase,
look for evidence supporting or refuting your theory,
and attempt to construct a minimal reproduction.
Report: your theory, evidence for and against,
confidence level (%), and reproduction attempt result.The outcome is a structured evidence matrix across four theories. Even if only one theory is correct, the other three reports give you high confidence you've eliminated those causes—which is often as valuable as finding the bug itself.
If you already have a strong intuition about the cause, resist the temptation to tell your agents. Even framing the task as "I think it might be a race condition, but check the other theories too" will bias agents toward confirming your prior. Give each investigator their theory and nothing else.
Use Case 4: Cross-Domain Architecture Review
System design reviews suffer from the same perspective problem as code reviews, but the stakes are higher—architectural issues are expensive to fix later. A team of domain-specialized architects can produce a more thorough review than any single generalist, because each expert builds deep context in their domain rather than shallowly covering all of them.
TEAM:
DataArchitect → Schema design, data flow, consistency guarantees
APIArchitect → Endpoint design, versioning, backward compatibility
SecurityArchitect → Authentication, encryption, threat modeling
ScalabilityArchitect → Query plans, caching strategies, load handling
PATTERN:
Each architect reviews the full system design document,
but focuses their analysis and recommendations on their domain.
Lead synthesizes into a prioritized action plan with
effort estimates and risk assessments for each recommendation.This pattern is especially useful before major architectural changes—a database migration, a new authentication system, or moving from monolith to services. The synthesis step often surfaces cross-domain conflicts (the security recommendation that conflicts with the scalability approach) that would be invisible in a single-expert review.
Use Case 5: Research and Content Creation
The researcher-writer-reviewer triad is one of the most efficient team patterns for content work. The key insight is that these three roles have different cognitive modes that don't mix well in a single context: research requires broad scanning and information gathering, writing requires deep focus on narrative flow, and reviewing requires critical distance.
TEAM:
Researcher → Gather technical information, examples, recent developments
Writer → Compose narrative with coherent structure and flow
Reviewer → Check accuracy, tone, completeness; suggest improvements
WORKFLOW:
1. Researcher: broad scan → structured outline → example cache
2. Writer: receives outline + examples → writes draft
3. Reviewer: reads draft → edits for clarity, flags inaccuracies
4. Writer: revises based on reviewer feedback → final draft
PARALLEL OPPORTUNITY:
While Writer composes section N,
Researcher can gather additional examples for section N+1.Teams that were spending 60 minutes on a technical blog post often cut this to 20–25 minutes with this pattern. The time savings compound at scale: a 10-article editorial calendar moves from a week of work to a day.
Use Case 6: Database Migration Coordination
Migrations are high-stakes, multi-phase operations where a failure in any phase can corrupt data or leave the system in an inconsistent state. The migration team pattern isolates each phase and introduces a verification agent that runs independently of the migration itself—catching errors that the migration agent might rationalize away.
TEAM:
SchemaAgent → Design target schema in the new database
DataMigrationAgent → Write transformation scripts, handle edge cases
VerificationAgent → Independently validate data consistency post-migration
RollbackAgent → Prepare rollback procedures in parallel (runs always)
KEY INSIGHT:
RollbackAgent works in parallel from the start.
You want rollback procedures ready before migration runs,
not after something goes wrong.
VerificationAgent is independent of DataMigrationAgent
so it can catch errors that the migration agent would miss
(the agent that wrote the migration is invested in it succeeding).The independence of the VerificationAgent is crucial. An agent that wrote the migration scripts is psychologically invested in their correctness—it will find ways to rationalize ambiguous results. An independent verifier, working from only the original schema and the target schema, will flag discrepancies without that bias.
Use Case 7: Parallel Performance Investigation
Performance problems are often multi-layered: the symptom is a slow endpoint, but the cause might be a missing index in the database, an N+1 query pattern in the ORM, a large synchronous computation blocking the event loop, or a missing cache layer. Each of these requires a different investigation technique, and they can all run in parallel.
TEAM:
DatabaseAgent → Analyze query plans, index usage, slow query logs
APIAgent → Profile endpoint execution, identify synchronous bottlenecks
FrontendAgent → Analyze render cycles, bundle size, component performance
CachingAgent → Map cache hit rates, identify cacheable operations
EACH AGENT PRODUCES:
1. Top 3 issues found in their layer
2. Estimated performance impact for each
3. Concrete fix proposal with effort estimate
LEAD SYNTHESIZES:
- Prioritized fix list (highest ROI first)
- Cross-layer conflicts or interactions
- Recommended implementation orderThe Check-In Model for Long-Running Teams
For projects that run longer than thirty minutes, you need a different management rhythm than for short sprints. Agents can drift, encounter unexpected blockers, or make assumptions that compound over time. The check-in model gives you regular visibility without requiring you to watch every pane continuously.
# Every 5 minutes during a long run:
"Status check: current task assignments and ETA to completion."
Lead responds:
✓ Database schema complete (finished 5 min ago)
🔄 Backend implementation (estimated 8 min remaining)
⏳ Frontend waiting for API contract (will start in ~2 min)
⚠ TestAgent: blocked — waiting for Frontend to finish
# If any agent stuck for more than 5 minutes:
"Can you check on [AgentName]? What are they working on
and is there anything blocking them?"The check-in prompt also serves as a forcing function for the lead agent to actively communicate with its teammates. A lead that hasn't checked in with the team recently will often discover, upon being asked for a status update, that an agent has been silently stuck for several minutes.
Each use case in this module follows a recognizable pattern: competing perspectives (code review, architecture review, debugging), contract chains (full-stack features, migrations), or parallel investigation (performance, research). When you encounter a new problem, ask yourself which pattern it resembles — then adapt it rather than designing from scratch.